


ABSTRACT
Due to the high performance of Tunnel Boring Machines (TBMs), the share of mechanised tunnelling in the overall tunnel construction market is rising constantly. These machines are equipped with a vast number of sensors to allow the personnel to monitor and report the operations involved and, ultimately, to further improve the machines’ and the jobsites’ efficiencies.
The data from the sensors open up opportunities to apply Data Science (DS) techniques for further automation and optimisation of tunnelling processes.
The challenges associated with DS in mechanised tunnelling and the need for specific skills and resources to develop solutions will be discussed, following an overview of the opportunities that DS offers to the tunnelling industry. Pivotal use cases and hands-on experience from implementation will be highlighted.

INTRODUCTION
TBMs have revolutionised the field of underground construction. Compared to the conventional drill and blast method, mechanised tunnelling greatly increases efficiency, reliability, and safety. Moreover, advances in micro-sensors, cloud technologies, and computational power grant access to a vast amount of data produced on-site, which has increased opportunity to apply DS techniques in this sector.
At Herrenknecht, specialised competence teams have been set up to develop DS working models from which specific solutions are derived.
Traditionally, TBM operators have to rely primarily on empiricism based on experience, biasing the data between different drivers and consequently increasing the complexity of automating processes using datadriven solutions.
Furthermore, the rise of Artificial Intelligence (AI) has compelled industries to a rapid digital transformation which often faces significant reservations. However, the use of data-centric algorithms would greatly benefit the processes conducted during construction, and, for this reason, researchers have recently shown increasing interest in Machine Learning (ML) in this field. Figure 1 shows the number of scientific publications that focus on the use of ML in mechanised tunnelling, a strong indicator of the growing interest and recognition of the benefits in the sector1.
This article may be seen as a follow-up to Glueck and Glab2, and aims to bring awareness of the potential of DS methodologies. Following on from what we learned during the development and deployment of our models into the TBMs, we report about major challenges and the main stages of a DS project.
DATA SCIENCE
“Data Science is a field of interdisciplinary expertise in which scientific procedures are used to (semi) automatically generate insights from conceivably complex data, leveraging existing or newly developed analysis methods. The knowledge gained is subsequently utilised, taking into account the effects on society.”3
DS is a collective term, including aspects of various disciplines such as ML, AI, data analysis, statistics, informatics, programming, cloud-computing, mathematics, and their variants. Broadly speaking, it aims at generating knowledge from typically large datasets.
For numerous businesses, the rapid technological advancement in the 21st Century has made it crucial to invest first in the acquisition of data, to then subsequently use DS to generate ‘value’ from the gathered information4. This value can refer to a wide range of solutions from, for example, digital services and products up to providing insight into processes and operations. However, the quality of the data drastically affect the results from a DS algorithm. Consequently, establishing a robust and reliable information base is key to leveraging the benefits of such technology.
In the tunnelling sector, the data infrastructure must successfully handle the vast amount of information generated during a construction project. To give an example, consider a TBM equipped with 2000 sensors writing data into a database at a regular sampling every second. Over one year the acquired time-series data totals to more than 200GB.
Since the amount of information is too vast to be analysed individually by statisticians, DS comes into play.
AI algorithms implemented by data scientists can process massive volumes of data – even in real-time – to create solutions that improve business performance. The strength of these algorithms is that they recognise patterns in high-dimensional data that cannot be perceived by humans. Prominent cross-industry fields of application are ‘anomaly detection’, ‘predictive maintenance’ and ‘remaining useful life’. These solutions help the tunnelling industry to reduce operational costs and energy footprints, improving their performance, make smarter decisions, achieve business growth, and much more.
Although not yet fully widespread, the deployment of DS applications in TBMs is steadily increasing due to the advantages aforementioned. Herrenknecht aims to unleash the potential of AI to its range of tunnelling technologies.
USE CASES
As mentioned in the prior section, the purpose of DS is to generate ‘value’ out of the numerous data recorded. Data-driven solutions offer potential for a multitude of areas in tunnelling, including operational optimisation5, maintenance and diagnosis6, modelling, and automation, to name just a few.
The following sections showcase specific applications that we have worked upon. These ‘use-cases’ may be seen as representative of a large number of DS applications in the field of mechanised tunnelling.
Anomaly Detection
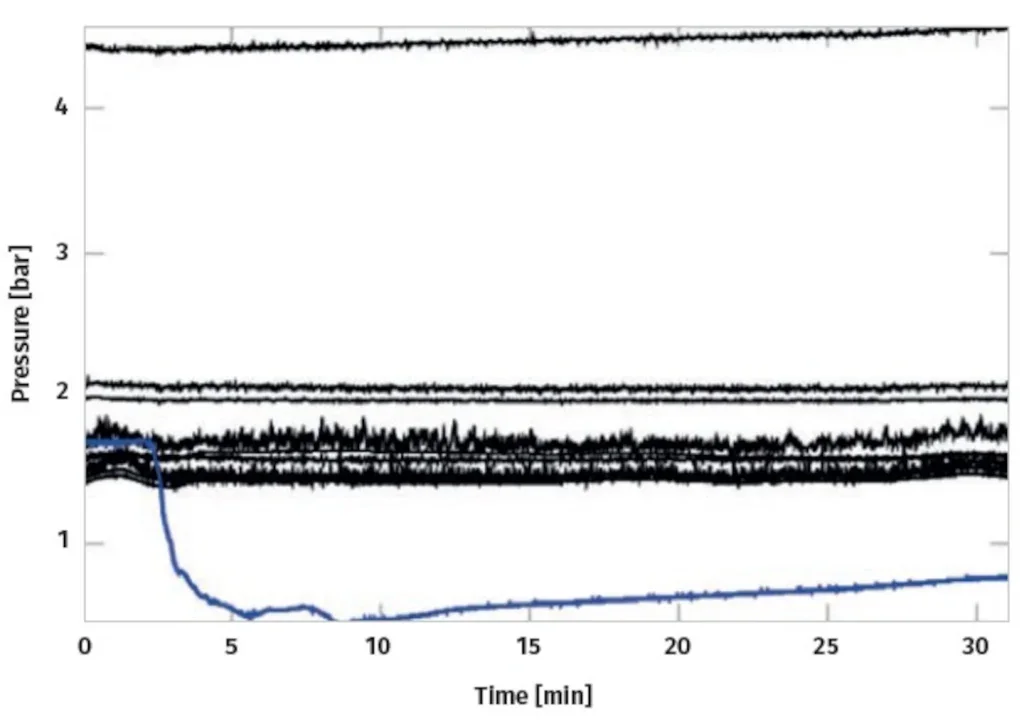
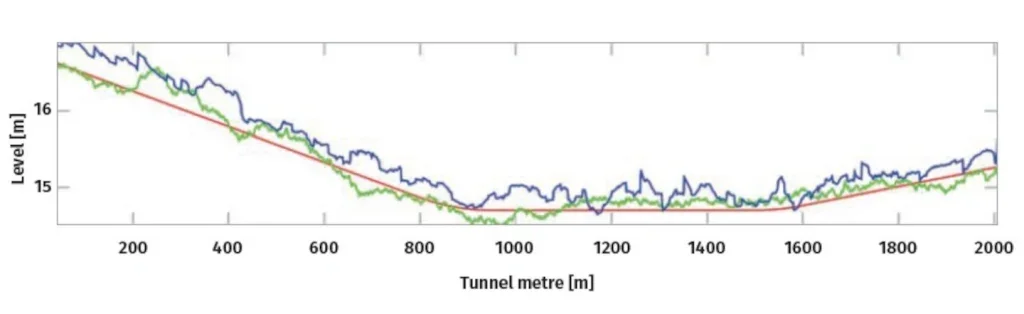
Quoting Mehrotra, Mohan, and Huang “anomalies or outliers are substantial variations from the norm”7. The early detection of abnormal behaviours in time-series data – e.g., such as caused by mechanical faults – is an important aspect of ensuring the operational readiness of TBMs. To give an example of what is meant, and to establish the link to TBM technology, Figure 2 illustrates the anomaly of a pressure sensor signal (drawn in blue).
At Herrenknecht, anomaly detection is facilitated by means of classical hypothesis tests, a well-established and solid foundation for detecting anomalies. The underlying assumption is that the distribution function of the regular process is known. Any deviation from this distribution, specified by an appropriate significance level, is considered anomalous.
An example of such a test is as follows. Considering the data shown in Figure 2, it is assumed that the pressure distribution in the excavation chamber is known. To a first approximation, the pressure depends only on the vertical position of the sensor. Therefore, it is common to approximate the vertical change in chamber pressure being constant8, eq. 6.
Herrenknecht considers a more elaborate description because of a non-vanishing shear modulus of the soil paste9. If the noise behaviour is analysed from the past, the pressure distribution can be described. In combination with an ordinary Analysis of Variance test, this is sufficient to discriminate the anomaly shown in Figure 2. Following this approach, the data of selected Herrenknecht TBMs are constantly processed, and in case of an anomaly, the staff is informed. The advantage of such an application is that it helps to avoid faults in the monitored component, preventing a costly machine’s standstill or even mechanical damage.
Geology Prediction
The prompt reaction of the TBM’s operator to geological conditions greatly affects the overall performance of tunnel construction. In particular, a late response to environmental changes may result in a serious accident10.
Therefore, before excavating, a team of geologists conducts intensive analysis to characterise the ground by means of borehole sampling, laboratory testing, remote sensing, etc. The information is then used to develop a geological model that TBM operators utilise to select the advance parameters that optimise the efficiency of tunnelling construction. Even though this model provides insight to the subsurface, it is known that its local accuracy may be scarce due to the sparsity of the measurements during environmental assessment11. Consequently, researchers have focused on exploiting TBM sensor data and using ML methodologies to infer the encountered geological conditions12.
The majority of literature addresses ground characterisation as a classification problem, aiming to predict the category of the ground by inspecting TBM data. Multiple ML methodologies were studied to solve this issue, namely ‘supervised’, ‘semi- supervised’, and ‘unsupervised’ learning.
A ‘supervised’ model establishes a mapping between the input and the labelled output that can be used to predict unseen data. Several works13,14 show that common ML models are able to successfully grasp underlying semantics in the data to characterise the lithology.
However, providing reliable labels for the training data is not always feasible as a universal classification system of geological units is not available. For instance, a granite section can behave drastically differently depending on additional environmental parameters. Consequently, these studies mainly focus on individual projects to train and evaluate the models. These drawbacks make this methodology unsuitable for detecting geology types in real-time for multiple tunnels, and, therefore, hinder their applicability in construction.
Another research direction is to use ‘unsupervised’ learning methodologies to avoid the use of scarce and erroneous labels. Zhang, Liu, and Tan13 used the K-mean++ clustering algorithm to characterise the data into a predefined number of geological units and an classical ML classifier was used to perform the final predictions. Although ‘unsupervised’ learning methods have the advantage of automatically attributing labels to the data, their performances are highly sensitive to noise and the set of selected features, limiting the models’ generalisation. Herrenknecht is currently exploring this ‘unsupervised’ learning methodology to differentiate operator actions in geological sections.
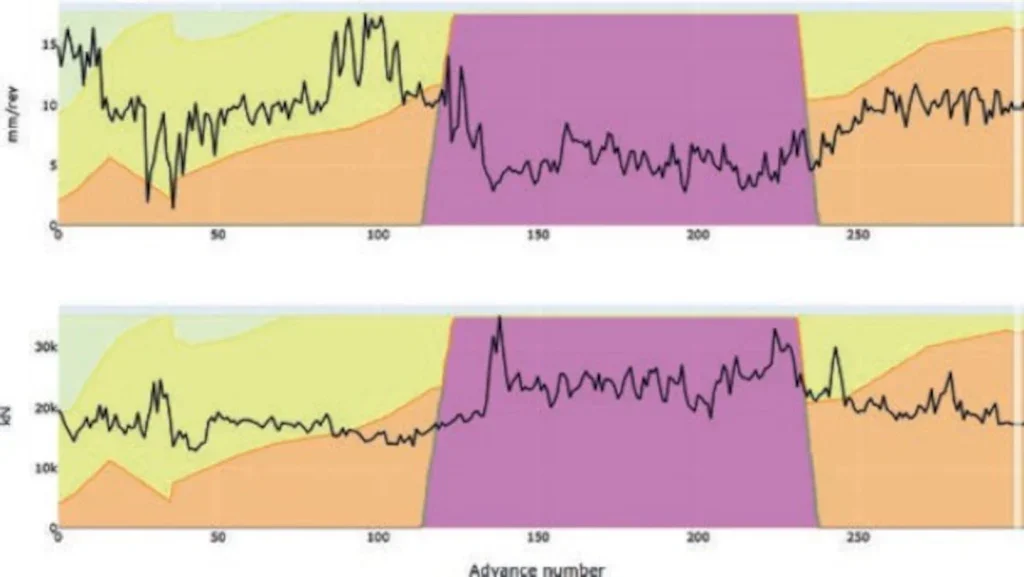
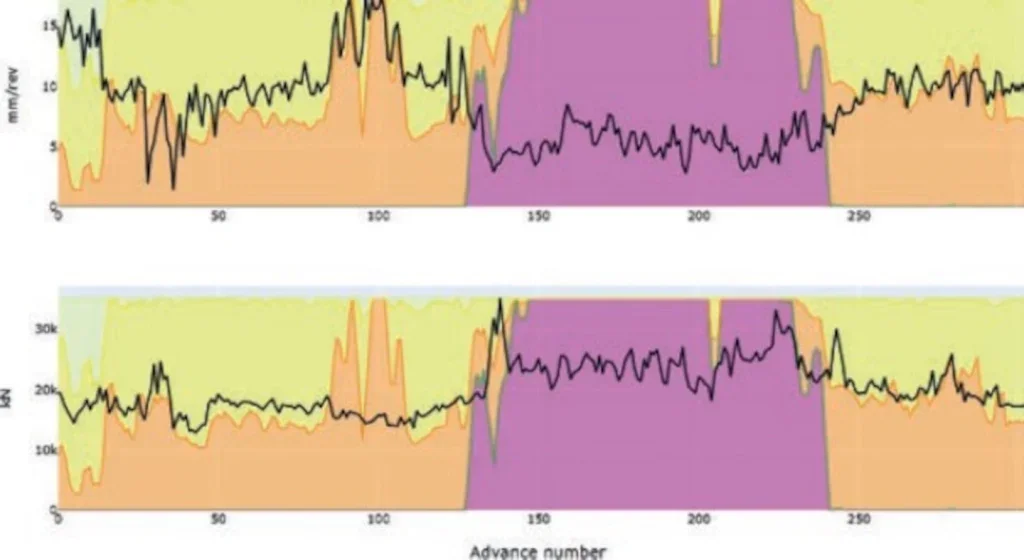
A ‘semi-supervised’ approach was proposed by Yu and Mooney11 in which tunnel advances are represented as nodes in a similarity graph, and the borehole characteristics are used to label the respective segments. The geological conditions are then learned by spreading the information in the labelled nodes with their neighbourhoods in an iterative manner, showing potential in addressing the issue of generalisation and tolerable performances in a real-time setting. The model developed by Herrenknecht is built upon this approach and aims to assist the operator by updating, in real-time, the geological cross-section. An example of how the result looks is presented in Figure 3. There, the assessed geological units are shown together with the inferred ones, showing higher agreement with the machine’s data.
To conclude, the topic of inferring lithology by exploiting the richness of TBM data together with recent advancements in ML methodologies is currently under research and development in the tunnelling community. Herrenknecht is investing resources in this application as it promises great potential for various other use cases. For instance, since geology significantly influences parameters during excavation, the inferred information could be used to optimise the parameters used for machine advance, leading to improved performances and reduced construction costs.
Performance Optimisation
Among the major aspects of the design of a tunnel is the expected time of construction, cost control, and the selection of the proper excavation method to reduce the overall cost of the project.
Researchers have worked on the prediction of the main performance parameters to assess the TBM excavation rates by employing mathematical and empirical solutions first, then adapting ML methodologies.
In the reviews published by Li et al.15,16 the authors summarise the research outcomes on a shared TBM dataset for performance prediction, showing reasonable accuracy in forecasting the thrust force and torque considering previous tunnelling information. In this context, special Artificial Neural Networks (ANN) that are called Long-Short Term Memory (LSTM) models are widely used. Zhou et al.17 used a bi-directional LSTM model to encode the previous 40 seconds of features and combined this information with the operational parameters using an attention mechanism to predict the mean of the thrust force and torque in the stable phase of the excavation cycle.
The natural extension of such an objective is the optimisation of the predicted parameters. Consequently, Lin et al.8 developed an ANN able to reflect the relationship between the operations, the construction environment, and TBM performance. Once the model was able to simulate these characteristics, the authors trained a physics-informed deep reinforcement learning model called TD3 that extends the classical Q-learning algorithm. The model showed improved performances when a physics-informed reward function was used to optimise the advance speed while keeping the pressure of the excavation chamber balanced with respect to the earth pressure.
Overall, the advances in ML methodologies in predicting and optimising the performances in tunnel construction show the feasibility of data-driven approaches in developing smarter TBMs. However, there are still limitations to overcome. In fact, the reported contributions never consider the geological conditions in their works for the challenges mentioned in the prior section immediately above (‘Geology Prediction’), and the designed target only considers a few of the parameters used in mechanised tunnelling, underestimating the complexity of operations. Finally, as the models are mainly tested on only a single tunnel it is hard to estimate the capacity of these methodologies for generalised application across multiple projects (to be discussed in the next section).
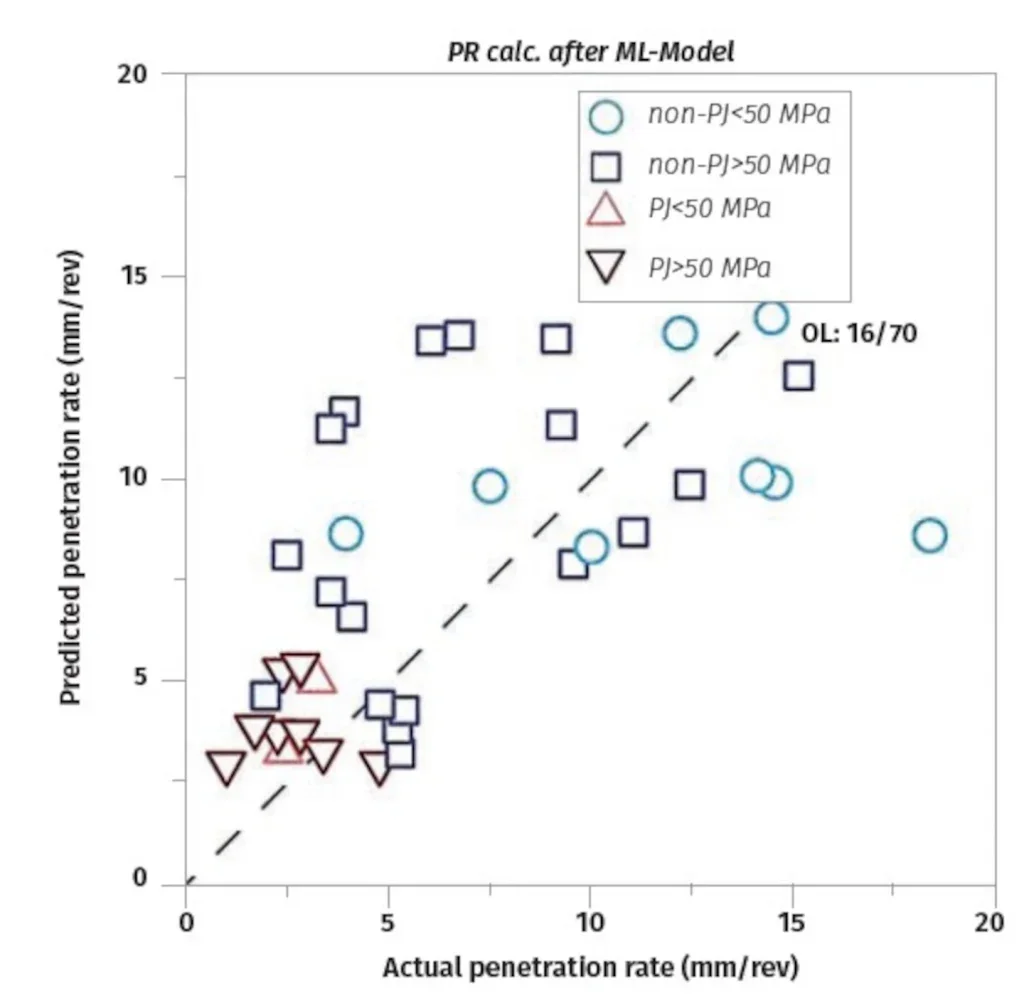
A work accomplished by Lehmann et al.18 at Herrenknecht considers the aforementioned challenges for the task of performance prediction for smalldiameter TBMs. A major challenge was the inspection of geotechnical reports, naturally affected by uncertainties. Admittedly, in the light of ML, the resulting database, covering lithological information, unconfined compressive strength, tensile strength, and point load index, is comparatively small. Nonetheless, the resulting model is able to unify the conventionally addressed models. The predictive performance of that model is illustrated in Figure 4. On the other hand, taking the efforts into account, it may well make sense to focus on specific cases rather than unifying over several parameters. One of the lessons learned is to carefully balance whether to prefer ML over a classic approach.
Directional Control
Autonomous steering control is a compelling research branch that aims to overcome the complexity of manual operations in controlling the attitude of a TBM during excavation. Currently, TBM drivers need to consider a large set of parameters that include deviations, operating states, geological conditions, etc., to control the thrust system and/or the shield articulation which affect the direction of driving. However, strong inertia and time delays constitute a major challenge that has to be faced along with the uncertainty of the geological conditions.
Data-driven approaches may play an important role in precise TBM steering. Recently, Zheng et al.19 published a survey that systematises existing approaches from the perspective of hierarchical control theory. Three layers are identified:
- The ‘perception’ layer aims to acquire details regarding deviation, operational parameters, and geological conditions. This task is accomplished by means of sensor technology and/or inferred from the data following the methodologies reported in the last two sections (‘Geology Prediction’, and Performance Optimisation’).
- The ‘decision’ layer is responsible for sending appropriate commands to the steering system, in order to follow the Design Tunnel Axis/Alignment (DTA).
- Finally, the ‘execution’ layer is responsible for ensuring that the thrust and/or articulation system accurately follows the selected actions.
Undertakings at Herrenknecht in this regard are based on research aimed at the automation of directional control for pipejacking TBMs20. The basis of this work is formed by a simulation that calculates deviations for a given series of shield articulations (‘perception’ & ‘execution’ layers). The ‘decision’ layer is formed by different controller types, ranging from ordinary linear controllers to a pre-trained LSTM network. Figure 5 depicts the vertical position that results from a multiinput single-output controller with proportional and integral part. The work shows that we are able to approximately simulate the data-generating process. However, pursuing with ML, a synthetic experiment in which a LSTM took over the steering was found severely biased towards the training dataset. The consequence is to adapt the controller – namely the LSTM – as widely as possible to all the conditions that may occur.
Reinforcement learning is the methodology that increasingly appears in the literature to solve such a task. However, this methodology highly depends on the simulation environment in which the agent is trained and, therefore, their applicability in real tunnels remains unclear. A work that follows such structure is presented by Fu et al.21 where a graph convolutional network and a LSTM are used to learn the spatio-temporal relation to provide an estimation of TBM deviations. The established meta-model is then employed in the optimisation process to generate ideal solutions through a nondominated Sorting Genetic Algorithm from which the most suitable action is selected.
Herrenknecht currently has under development an automatic steering control to aid TBM operators in manoeuvring the machine. The generalisation of such a product for application to new tunnels is a major challenge.
CHALLENGES
In the last decades, the world has faced a transformation that forced many industries to rapidly adapt to the emergence of AI. Due to its strong engineering background and niche business area, the tunnelling industry faces exceptional challenges to unleash the power of this new technological breakthrough. The following section discusses a sample of these challenges – and proposes solutions.
Domain Knowledge
As indicated in the previous section regarding Use Cases, a profound understanding of the complex operations encountered in tunnelling is vital for the development of data-driven solutions. Experts pooling a deep comprehension of mechanised tunnelling, a geological background, broad DS skills, and deployment experience are particularly rare.
Herrenknecht is developing data-driven solutions typically in a team of multiple experts with different backgrounds. Data scientists are required to tightly cooperate with domain experts of TBM components involved in the developed application and vice versa.
One challenge is the communication with the different ‘languages’ that data scientists, engineers and developers use. A strong mediation between the parties is recommended to mitigate such a problem.
In view of the global shortage of qualified data scientists, Herrenknecht expanded its competence base by establishing various cooperations with German and international universities and research institutes.

Data
In general, the power of AI thrives on the quality of the data. The tunnelling sector has its unique challenges with regard to this resource. We loosely differentiate three types of data:
i) Operating – This includes the entire sensor system, such as strokes, pressures, voltages, speeds, fill levels, navigation, and even videos. These data can be processed comparatively well because the majority of records are stored in a structured manner. Typically, a timestamp is used for indexing and time-series analyses can provide great insights on the patterns that arise during machine operations.
When collecting this data, we encounter a number of pitfalls. One of them is inconsistent naming and typos due to the high degree of customisation. Occasionally we are faced with information losses, such as missing time zones, representation of invalid numbers or a loss of precision due to type conversions.
ii) Meta – Without additional information, often the pure operating data cannot be evaluated. Those metadata include, for example, construction drawings or specification sheets. The manufacturer typically provides this information prior to excavation.
These data are usually exchanged in formats accessible to humans rather than being machinereadable. Consequently, every DS application maintains parameters individually, which leads to proliferation and redundancies.
iii) Secondary – Data that are outside of our influence sphere are the most challenging aspect for us. This is a very broad range that spans geotechnical information, the DTA, contracts but also job site reports. These data are stored as structured and/or unstructured, and there is no control over language, form, format, units, coordinate systems, etc.
One challenge is the unstructured and humanreadable geotechnical reports. In fact, not only few reports arrive as hardcopy and every exploration contractor is using its own patterns, metrics, units and parameters. Consequently, reading off the entire borehole information manually is prone to errors. Nonetheless, Herrenknecht was able to successfully bring the geological cross-section into our data platform22.
Reports about the tunnelling process are valuable information for DS applications. As an example, when it comes to predicting the wear of excavation tools, the expectation is quite understandable. The prerequisite for such a development, however, is consistent wear documentation of high quality. To our experience, such data-sets are hardly maintained, rendering data-based solutions unfeasible.
The aforementioned challenges can be mitigated with the establishment of a standard for a consistent data acquisition. Moreover, additional effort is needed in data collection – involving on-site personnel – for widespread data-based solutions in tunnelling.
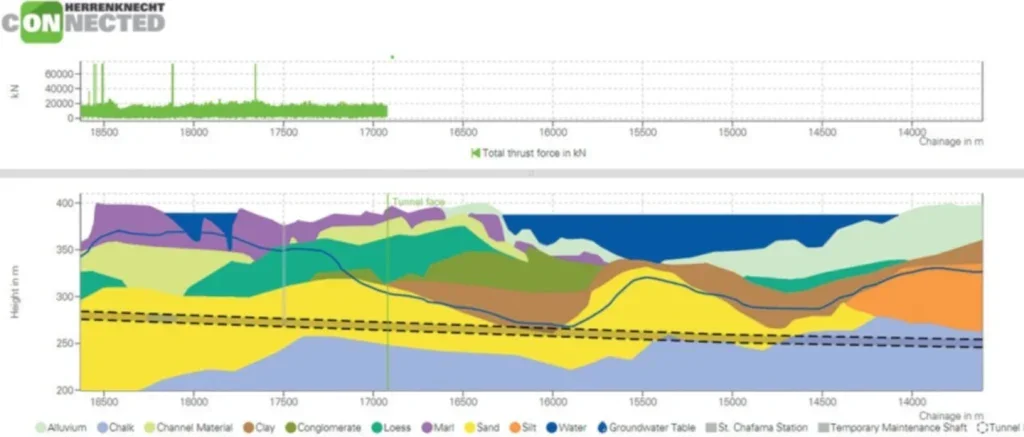
Herrenknecht is investing a significant amount of resources to provide a reliable infrastructure for the collection of data generated from the customers’ TBMs. With our service Herrenknecht.Connected we are offering a web-based interactive interface, that is capable of providing all the information described above22. As an example, Figure 6 shows the total thrust force together with the geological cross-section to easily inspect if different geological unit leads to differences in the TBM’s performance.
Preprocessing
The raw data acquired on TBMs are typically not ready for use by AI applications. The majority of data require careful cleaning and preprocessing to extract features, individually tailored to the needs of the use case.
The harsh conditions underground cause a significant amount of anomalous and void measurements, and, occasionally, sensor faults may occur. Because TBMs are highly customised, e.g., sensors are individually positioned, every project requires its own data cleaning rules and strategies.
In fact, the preprocessing involves more than dealing with corrupted data. It covers the conversion of units, e.g., imperial to metric as well as the mapping of coordinate system, e.g., between latitude/longitude and the job-site system. In most situations, it is necessary to filter the data targeted to the use-case. For example, we often remove the data during standstill (ring-building, maintenance, etc.). If only advances are relevant, then the time domain is usually an unfavourable parameterisation. Therefore, a common preprocessing step is to re-parameterise according to the arc length of the tunnel. Subsequently, the distinction between chainage and tunnel-metre requires additional attention.
A company needs notable computing resources to preprocess the average volume of TBM data, especially when performing cross-project analyses. According to our experience, cleaning and preprocessing is highly bound to use-cases and consumes up to 80% of time spent on a DS project.
Generalisation
As reported in the previous section Use Cases, most of the developed AI applications focus on single tunnels. The reason is that a TBM is highly customised to excavate certain geologies on a tunnel project, which hinders the possibility of identifying unified features to derive patterns that can be applied to other projects.
This is the challenge of generalisation – which actually comes as a threefold challenge.
The first aspect of the generalisation challenge is that features and targets are required to be comparable across tunnelling projects as well as TBMs. In fact, the data describing the torque generated by a 12m-diameter TBM is in a completely different range of magnitude compared to the data of a 6m-diameter shield. Moreover, also the number of components – e.g., hydraulic cylinders, motor cutting wheels, etc – may differ, making every TBM almost unique.
When it comes to cross-project analysis, however, it requires more than having properly scaled features and targets. If a dataset is well-balanced, the characteristics are similarly present. As an example, if we want to infer something about the influence of geology, the relevant geologies should be represented to a similar degree on different projects. If a certain geology dominates, it is likely to receive a biased result. Another example is that some pilots prefer to use the shield articulation whereas others the thrust system. In order to be able to lump the datasets together, a strategy is required to compensate for the bias.
Assuming we can solve the first two points, then, the problem of transferring this knowledge to a new, unseen tunnel project remains. However, historic projects with similarities of construction ground, TBM diameter and type (earth pressure balance (EPB), Mixshield, Gripper, etc.,) are rare. At this point, an algorithm is needed that is able to interpolate amongst the historic projects available in a database.
Herrenknecht also carried out research in that direction. Rehnuma Shabnam23 analysed the change of direction across multiple TBMs. One finding was to balance the presence of sections pointing right, left, up, down and straight. We were able to balance the ratios by using Transfer Component Analysis for domain adaptation.
We see enormous future potential in generalising across tunnel projects because it offers the opportunity to carry out predictive and evidence-based design studies.

Deployment
A ML model that aims to improve tunnelling operations must be made available in order to turn the inferences into a practical solution. As soon as a data-based solution is about to leave the pilot stage, it is time to take scalability across the fleet and the required IT landscape into consideration. With larger fleets, there is a risk that routine tasks, such as configuration, rollout and maintenance, will tie-up significant amounts of resources. A high degree of automation is therefore recommended for operationalisation.
The process and procedures to make a software solution available is called ‘deployment’. The first step in ‘deployment’ is to ensure configurability, followed by packaging and versioning. Once in operation, maintenance and updating procedures must preserve configuration and acquired data. Indeed, for all those technical aspects a solution needs to be readily available.
‘Deployment’ is not the prime expertise of data scientists and, therefore, a close collaboration with software engineers is vital to ensure reliable infrastructure to bridge the gap between experimentation and stable DS-based application.
On behalf of our customers, Herrenknecht operates several hundred industrial computers on TBMs. Therefore, Herrenknecht took considerable efforts to build a customised ‘deployment’ system24, which is equally used for delivering data-based solutions to our TBMs. We use containerisation to bundle application codes together with the designated software environment. A state-based automation engine maintains configurations and updates. A compute cluster is used for virtualisation and orchestration. An inhouse service-platform serves for the roll-out, monitoring and maintenance of the entire fleet. Such infrastructure ensures high reliability and the continuous integration of new features in the system, and therefore, customers can benefit from the latest version of the application.
Although this system is very powerful, it is not all-encompassing. Adjustments at the Programmable Logic Controller (PLC) code still require a considerable amount of manual effort. This is why the DS-related tech-stacks seek a solution to fuse with proprietary PLC tooling, together with its legacy code-base. For small projects we use code-converter to translate high-level languages – e.g., MATLAB – into PLC code. Computationally demanding tasks often receive dedicated edge devices (AI/ML/DS), and communication with the TBM is established via Open Platform Communications (OPC).
DATA SCIENCE ROADMAP
So far, we have had a look at the potentials and challenges of using DS for mechanised tunnelling. Next, we consider how to get started with DS projects and what this will take.
If there are no DS initiatives then the ‘playbook’ by Ng25 is a good starting point. Because it was valuable advice to kick-off with so-called ‘low hanging fruits’ in order to bridge the gap for more, we want to share our success story.
We started out by deliberately leaving ideation, assessment, structure, and strategy aside, and focused on what we were capable of. Equipped with a vague goal but without a work breakdown structure, the data scientists went straight into an agile development (work principles focused on how a team collaborates). While iterating, that approach gave us the opportunity to gain practical experience and to form a functional team. In our opinion, successful projects, no matter how small, create acceptance within the company and among customers. This lays the foundation for DS to establish itself.
However, as the number of projects increases, there needs to be more than a focus on getting to work straight away. After a number of endeavours, we have found that agile working principles, and also a process model, leads to increased efficiency. Having both does not mean to establish dual structures. While the agile principles focus on team collaboration, the process model is more focused on the steps to execute a DS project.
Agile Work
DS is a rather young discipline and it is developing at a rapid pace. On short time scales, new solution strategies are opening up. Consequently, we regularly find ourselves in a voluntary, uncertain, complex and ambiguous planning situation – and this where using an agile approach proves a strength. At the same time, we have learned that classic project management is more suitable for small projects, with a specific goal and intuitive solution.
The origin of collaborating the agile way finds its roots in software development. A much-cited work is the ‘Manifesto for Agile Software Development’ by Beck et al. Agile working principles have developed into a general approach and are not limited to software development. The strength of an agile approach lies in its iterative nature. This makes it possible to address obstacles such as vague goals and unknown solution strategies as part of the process.
Probably the best-known agile process is ‘Scrum’27. However, although it is a general purpose tool, as a company with its roots in mechanical engineering Herrenknecht does not recommend adopting this process instantly, rigorously and in its entirety. In our experience, ‘Scrum’ only makes sense in very specific cases. As a rule of thumb, we debate ‘Scrum’ only in cases of vague goals, having more than three developers, and workload from estimated 150 man-days onwards.
We adopt bits and pieces of ‘Scrum’ whenever beneficial, e.g., back-log, iterations, sprint-goals, and quality. We often start a project with the fundamental concept and then sharpen by iterations. At the early increments of a project, it is quite intuitive to add specific functionality. The closer a project gets to its objective, the more important it becomes to add value per increment instead of getting lost in polishing. When filling the back-log, we experience the grouping of work-items by subsystems to be obstructive. Because requirements may change, it seems to us even more important to focus only on functionality that is required at the time. In an agile project, developing subsystems with foresight carries the risk of insufficient specifications.
We believe that these simple principles can be used for getting started with agile development instead of trying to plan for all the details in advance. Once agile concepts meet with acceptance, there is always the option of formalising the process.
Process Model
Industries that want to successfully adopt datadriven solutions are faced by numerous challenges, such as previously stated. We found it important to organise tasks, tooling and the necessary resources that characterise any DS project.
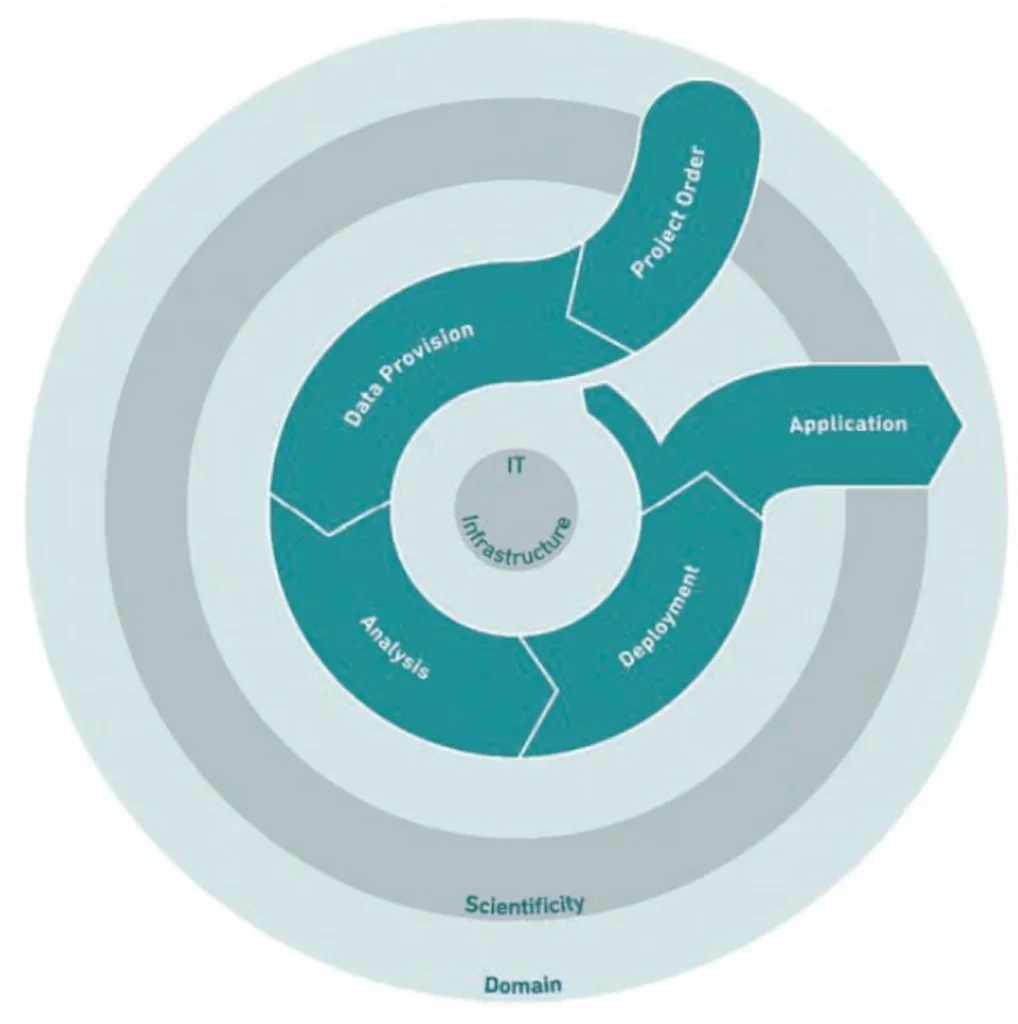
While process models in engineering are well established (e.g., waterfall- or V-model), process models devoted to DS are still in rapid evolution. Based on the review by Kutzias et al.28, we tested a rather new process model. Schulz et al.3 developed a process model called DASC-PM (see Figure 7) to assist practitioners in the main stages of development, which is described below together with our experiences at Herrenknecht.
Initially, a use case arises from a specific problem within a domain. In this phase, requirements, problems, resources, and risks need to be assessed to determine the necessary work-steps and create an outline of the project. It is important to note that not all of the above aspects can be clearly defined in advance, especially for those projects that focus on research and development of applications using new technologies.
Our approach for such a challenge is to subdivide the problem into smaller chunks that we believe being more feasible. However, we experienced that this practice may lead to variable intermediate milestones that do not always help in reaching the overall objective. Consequently, we recommend flexibility and an agile attitude for data scientists working on complex problems.
When the problem is formulated, DASC-PM introduces the phase called ‘data provision’ in which the steps to make the data ready for further analysis are identified. Firstly, the framework for the acquisition of raw data needs to be carefully established through sensor systems and documentation.
The task of data preparation aims to transform the data from the source system into a suitable format for the selected analytical method. As reported above, in the ‘Challenges’ section, this task can be troublesome and time-consuming.
The goal of achieving cleansed data is not always unequivocally possible in the early stages of a DS project, and, consequently, continuous assessment through extensive visualisation and statistical analysis is required. The provision of high-quality data is fundamental for the success of a DS project, and most of the time spent in the development of a product is related to this phase.
The phase then following relates to the identification of the best procedure to accomplish the goal. Since a final selection cannot be made without extensive evaluation, often multiple procedures should be considered first. Otherwise, data scientists should develop their own methodology. The result of this phase can take different forms, ranging from descriptive and diagnostic analyses to predictive and prescriptive models, ready for ‘deployment’.
In the ‘deployment’ phase, an applicable form of the analysis results is created. When the application is created, it should be continuously monitored to ensure the quality of the results and the long-term applicability of the model.
The above principles should help in establishing a high-quality DS product. Although at Herrenknecht we seek to work in accordance with this process model, we have found that such procedures are not always applicable. For example, we faced a use case in which the fast delivery of an application for monitoring a component of a TBM was a major requirement. Our solution was a very early ‘deployment’ phase, for which we made initial functionality directly available and then went back to the analysis phase to make iterative improvements.
To conclude, we believe that the points discussed above are important steps to deliver valuable DS products and accelerate progress in enabling increasingly smarter TBMs.
CONCLUSION
DS has emerged as a game-changer in many industries. By leveraging advanced analytics and ML methodologies, the tunnelling sector can improve operations while reducing risks, overall optimising the total cost of tunnelling. Consequently, in recent years researchers have increasingly focused on a broad range of applications in the underground sector.
However, two major aspects of the challenges reported in ‘Challenges’ section retard wide adoption of these applications in construction. One is the transfer of academic research to the tunnelling industry and the other is establishing acceptance for data-driven solutions.
In this regard, we summarise a roadmap containing important aspects for mastering DS-related projects in tunnelling. At Herrenknecht, the key finding to bring DS into practice is an in-detail understanding of the data in use. Since this knowledge is held by domain experts of relevant fields, we encourage their collaboration with data scientists to successfully solve use cases, while simultaneously promoting their acceptance. In addition, agile work principles – in particular of increments and adoptions – are beneficial to the continuous delivery of relevant solutions.
REFERENCES
- Shan, F., He, X., Xu, H., Armaghani, D. J. and Sheng, D. (2023) “Applications of machine learning in mechanised tunnel construction: A systematic review,” Eng, vol.4, no.2, pp.1516–1535.
- Glueck, K. and Glab, K. (2023) “Data science in TBM tunneling: Use cases, benefits and challenges,” in Expanding Underground – Knowledge and Passion to Make a Positive Impact on the World, edited by Anagnostou, G., Benardos, A. and Marinos, V. P. From CRC Press, ISBN: 9781003348030. Available: http://dx.doi.org/10.1201/9781003348030-323
- Schulz, M., Neuhaus, U., Kaufmann, J. et al. (2022) “DASC-PM v1.1 a process model for data science projects,” Available: http://dx.doi.org/10.25673/91094
- Philbeck, T. and Davis, N. (2018) “The fourth industrial revolution: Shaping a new era,” Journal of International Affairs, vol.72, no.1, pp.17– 22, ISSN: 0022197X.
- Glab, K., Wehrmeyer, G., Thewes, M. and Broere, W. (2022) “Energy efficient EPB design applying machine learning techniques,” in WTC2022, ITA- AITES. ISBN: 978-2-9701436-7-3.
- Weiser, T. and Tröndle, J. (2022) “Digital construction: Data management in mechanized tunnelling,” in WTC2022, ITA- AITES. ISBN: 978-2- 9701436-7-3. Available: https://library.ita-aites.org/wtc/2169-digital-construction-data-management-in-mechanizedtunnelling.html
- Mehrotra, K. G., Mohan, C. K. and Huang, H. (2017) Anomaly Detection Principles and Algorithms. Springer International Publishing. ISBN: 9783319675268. Available: http://dx.doi.org/10.1007/978-3- 319-67526-8.
- Lin, P., Wu, M., Xiao, Z., Tiong, R. L. and Zhang, L. (2024) “Physicsinformed deep reinforcement learning for enhancement on tunnel boring machine’s advance speed and stability,” Automation in Construction, vol.158, pp.105 234. Available: http://dx.doi.org/10.1016/j.autcon.2023.105234
- Mürb, J. (2020) “Weiterentwicklung und Implementierung eines Regelalgorithmus zur automatischen Schildsteuerung einer Tunnelvortriebsmaschine,” M.S. thesis, Hochschule Karlsruhe.
- Ji, J., Zhang, Z., Wu, Z,. Xia, J., Wu, Y. and Lü, Q. (2021) “An efficient probabilistic design approach for tunnel face stability by inverse reliability analysis,” Geoscience Frontiers, vol.12, no.5, pp.101210, ISSN: 1674-9871. Available: https://doi.org/10.1016/j.gsf. 2021.101210.
- Yu, H. and Mooney, M. (2023) “Characterizing the as-encountered ground condition with tunnel boring machine data using semisupervised learning,” Computers and Geotechnics, vol.154, pp.105 159. Available: doi: https://doi.org/10.1016/j.compgeo.2022.105159
- Mostafa, S., Sousa, R. L. and Einstein, H. H. (2024) “Toward the automation of mechanized tunneling – exploring the use of big data analytics for ground forecast in TBM tunnels,” Tunnelling and Underground Space Technology (TUST), vol.146, pp.105 643. doi: https://doi.org/10.1016/j.tust.2024.105643
- Zhang, Q., Liu, Z. and Tan, J. (2019) “Prediction of geological conditions for a tunnel boring machine using big operational data,” Automation in Construction, vol.100, pp.73–83. doi: https://doi.org/10.1016/j.autcon.2018.12.022
- Zhao, J., Shi, M., Hu, G. et al. (2019) “A data-driven framework for tunnel geological-type prediction based on TBM operating data,” IEEE Access, vol.7, pp.66 703–66 713. https://doi.org/10.1109/ACCESS.2019.2917756
- Li, J.-B., Chen, Z.-Y., Li, X. et al. (2023) “Feedback on a shared big dataset for intelligent TBM, Part I: Feature extraction and machine learning methods,” Underground Space, vol.11, pp.1–25. doi: https://doi.org/10.1016/j.undsp.2023.01.001
- Li, J.-B., Chen, Z.-Y., Li, X. et al. (2023) “Feedback on a shared big dataset for intelligent TBM, Part II: Application and forward look,” Underground Space, vol.11, pp.26–45. doi: https://doi.org/10.1016/j. undsp.2023.01.002
- Zhou, X., Gong, Q., Yin, L., Xu, H. and Ban, C. (2020) “Predicting boring parameters of TBM stable stage based on BLSTM networks combined with attention mechanism,” Chinese Journal of Rock Mechanics and Engineering, vol.39, no.S2, pp.3505–3515
- Lehmann, G., Käsling, H., Hoch, S. and Thuro, K. (2024) “Analysis and prediction of small- diameter TBM performance in hard rock conditions,” TUST, vol.143, pp.105 442. doi: https://doi.org/10.1016/j. tust.2023.105442
- Zheng, Z., Luo, K., Tan, X. et al., (2024) “Autonomous steering control for tunnel boring machines,” Automation in Construction, vol.159, pp. 105 259. doi: https://doi.org/10.1016/j.autcon.2023.105259
- Müller, F. (2023) “Entwicklung und Validierung eines Machine Learning Algorithmus zur Automatisierung des Schildsteuergelenks im maschinellen Tunnelvortrieb,” M.S. thesis, Hochschule Offenburg.
- Fu, X., Ponnarasu, S., Zhang, L. and Tiong, R. L. K. (2024) “Online multi-objective optimization for real-time TBM attitude control with spatio-temporal deep learning model,” Automation in Construction, vol.158, p.105 220. doi: https://doi.org/10.1016/j. autcon.2023.105220
- “Herrenknecht.connected,” Herrenknecht AG. (May 22, 2024). Available: https://www.herrenknecht.com/en/services/herrenknechtconnected/
- A. Rehnuma Shabnam, (2023) “Predicting the movement of tunnel boring machines with ARIMAX and transfer learning,” M.S. thesis, Otto von Guericke Universität, Magdeburg.
- Dimovska, E. (2024) “Zentrales Configuration Management und Überwachung von Edge- Devices,” B.A. thesis, Hochschule Offenburg.
- Ng, A. (2020) AI transformation playbook. how to lead your company into the AI era. Landing AI. Available: https://landing.ai/wp-content/uploads/2020/05/LandingAI_Transformation_Playbook_11-19.pdf
- Beck, K., Beedle, M., van Bennekum, A. et al. (2001) “Manifesto for agile software development”. Available: http://www.agilemanifesto.org/
- Schwaber, K. and Sutherland, J. (2020) “The scrum guide”. Available: https://scrumguides.org/docs/scrumguide /v2020/2020-Scrum- Guide-US.pdf
- Kutzias, D., Dukino, C., Kötter, F. and Kett, H. (2023) “Comparative analysis of process models for data science projects,” in Proceedings of the 15th International Conference on Agents and Artificial Intelligence – Volume 3: ICAART, INSTICC, SciTePress, pp. 1052–1062, ISBN: 978-989-758-623-1. doi: https://doi.org/10.5220/0011895200003393




